|
Data is the basis for many operations, but it doesn’t mean data is always reliable. Things can get complicated when you don’t know which data source is reliable and which is not. But we must use data all the time. Sometimes it is possible to increase the accuracy, but the more meaningful solution is to build a software layer to correct data before using it. I earlier wrote about known and unknown things and data points. The reality is even more complex. We know some data is relevant, and it is available, but we don’t always know how reliable it is. We all know about opinion polls and their error margins. It is just one example, but uncertainty is linked to all data sources and models that utilize data. In aeroplanes or nuclear power stations, the core systems do not necessarily trust individual sensors or data sources. There can be many reasons why a particular sensor gives incorrect data. For example, a pitot tube that measures an aircraft’s airspeed can transmit incorrect information if frozen, which has caused several plane crashes. Today, a plane typically has several pitot tubes, and the software tries to draw conclusions and give pilots warnings if one or more give inconsistent readings. Sometimes the situation is more demanding when it is difficult, even impossible, to know if data sources and sensors give accurate data and how large the error margin is. Examples of this are wearable devices. They can measure your exercise patterns, sleep, and body functions like heart rate, temperature or blood pressure. These devices are calibrated using higher accuracy devices during development. But it is still hard to say how accurate they are for different people in different situations. For example, even with top-level research instruments, it is not easy to measure how much light sleep, REM, and deep sleep a person has at night. We might also have a situation where we have many sensors, but some data might be missing. It is a complex task to combine data from different sources, and it is also tricky to know if available data makes any sense combined. This can occur when having many IoT sensors or an organization’s internal data from multiple sources to measure processes or even financials. It is often said that intelligence makes up only 20% of AI implementations, and the rest is getting data, combining it and correcting errors. This layer is often underestimated. I have seen projects where 95% of the data is inaccurate, incorrect, or missing data points. There are several ways to increase the accuracy of data, for example:
These layers combine, correct and smartly use data and become more important as we get more data sources. One could even say it is pretty simple to create AI models if someone has developed this layer to make reliable data available. It is often said that IoT business is not really to sell sensor hardware but to manage data, but what is ignored many times is the critical question of getting reliable data. It is not easy to make these layers that combine data because each source is different, and it can also require an understanding of the data to be able to analyze and integrate data sources. It is possible to make general models and tools for this, but they often need tailoring for the different data sources and combinations of data sources. With AI’s hands, these smart data combining models and layers become a vital part of the data and AI business. Data is valuable only if it is reliable. We can trust AI only if it can use correct data. The reality is that no data source is 100% reliable, so we need intelligence, how to correctly and optimally use data sources. The article was originally published on Disruptive.Asia.  Photo Source: Wikipedia, automatic landing system. It has become popular to manage operations with data. New tools to collect and analyze data are continually appearing. But things can still go badly wrong with data. Dashboards and analytics apps rely on multiple assumptions, and if external factors change, models don’t work anymore. COVID-19 activities in many countries have been good examples of this. When you don’t know all the elements, individual numbers can be misleading. You can never manage only by the numbers you have; you must have insight, understand the environment, and be ready to look for changes outside the numbers. Some years back, US Defense Secretary Donald Rumsfeld made the famous statement about known unknowns and unknown unknowns. Many people laughed at that statement, but it is quite an excellent way to describe reality, not only in war and foreign politics but also in business environments. Many companies focus on things they know, but they are not prepared to handle external factors they are unaware of. Many countries specified data-based recommendations and rules during the current pandemic, e.g. tier systems to close shops, services, restaurants, or varied travel restrictions. They are based on the number of cases per 100,000 inhabitants, people in hospitals, or the virus’s R-value (reproduction rate). But most governments have been forced to change those rules and thresholds many times. It has given reason for citizens and opposition parties to criticize their actions. The reality is that it is challenging and not very intelligent to manage only by a set of numbers if many factors remain unknown. This scenario makes sense to change rules and metrics as we learn more about the situation. Many companies focus on optimizing their operations based on the numbers they follow and measure. It is precisely why a disruption in an industry lands an incumbent company in trouble when they focus on numbers in the domain they know and recognize. Still, disruption often changes factors that they don’t monitor or are unknown to them. The most famous examples involved mainframe computer companies when personal computers came out; for Nokia, when Apple introduced the iPhone and print publishers when online content came. Those companies focused on optimizing their operations, products and metrics in the existing business and environment. For example, Nokia was optimizing the production costs of phones, model ranges for different customer segments and their software features. The iPhone looked too expensive based on their metrics, not suitable for many customer segments and had too few features for users. Known unknowns and unknown unknowns are relevant categories for businesses to analyze in more detail. Known unknowns are factors they know about but cannot get details or data on. For example, competitor’s future products, economic growth and the future availability of components. Unknown unknowns include factors that we don’t know at all but that are likely to impact us. The pandemic, for example, came as a surprise, and we had no idea what impact it would have on our lives and businesses. There are many factors we don’t know about or can even imagine, but they might have a lot of impact on us. We can also think of one more category, unknown knowns. It would mean things we know, but we don’t recognize how they impact us. For example, using available data but never thinking it will be relevant, like a company being aware of climate change data but not recognizing it as a factor in their business. However, if we only focus on the ‘known knowns’, we can still be surprised when something changes and still not understand the real reasons for it. Many businesses and people focus only on the ‘known knowns’ and try to understand and explain everything based on that, but then they miss those three other areas discussed above, and external factors surprise them, or they reach wrong conclusions if they don’t understand that things outside their focus have an impact. Can we do something to handle unknown areas better? Maybe the most important thing is not to think you know and understand everything, and that you must keep your eyes open for other things too. We can assume at least three categories of actions that you can do better with data and metrics:
The COVID-19 pandemic and its impact on governments, businesses and individuals has taught us how companies can and need to be better prepared for unexpected events. Some of them can be big significant global events, some smaller ones like why some sales go down and why people are no longer interested in a particular product. Maybe the most important things to remember are: 1) you cannot know it all; 2) your models are not perfect, and 3) when something unexpected happens, don’t think you can explain or handle it using old models only. As the famously coined Darwin quote goes, “the species that survives is the one that is able best to adapt and adjust to the changing environment in which it finds itself.” 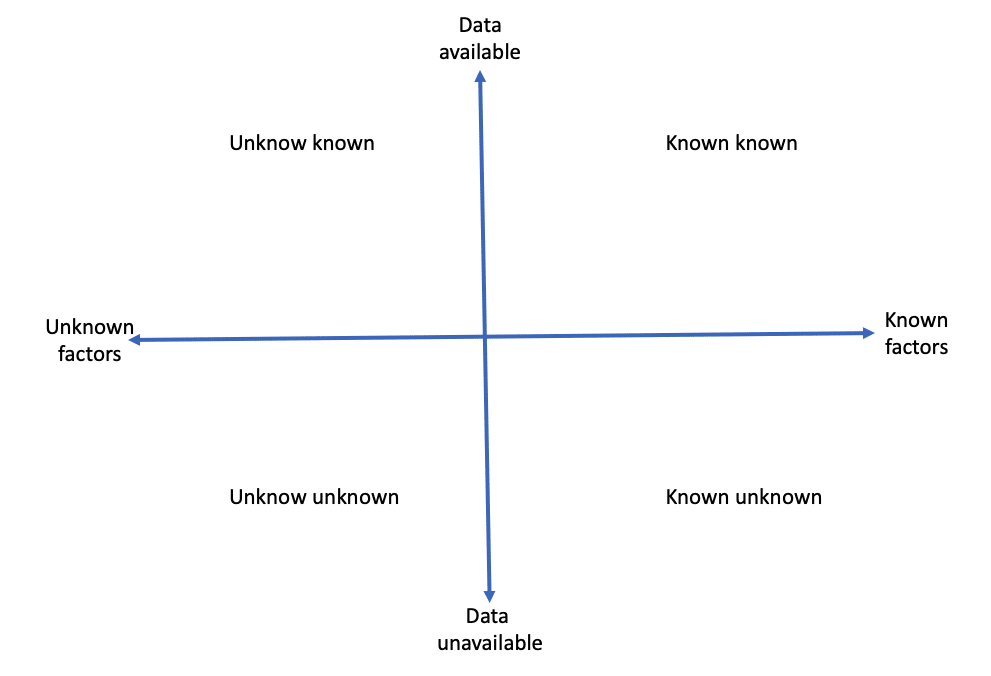 UK’s supreme court recently made a ruling classifying Uber’s drivers as workers entitled to rights such as minimum wage and holiday pay. Uber has a long history of legal battles. It has had many fights against taxi regulations, who can offer rides and how. But the struggle over the rights of its drivers is even more fundamental. It hits at the heart of its operating model and cost structure and it’s a good example of disruption versus regulation. The court ruling says that drivers not only work when they are on a trip but includes the time they are logged into Uber’s app. Amongst other things, Uber now needs to start a pension scheme for these drivers. It significantly increases Uber’s costs, and it fundamentally changes the idea that drivers are ‘entrepreneurs’ who get customers through Uber’s app. Californians voted on a similar question for their workers’ law in November. Uber spent a lot of money to get support for its model, and the results were that the drivers could continue as independent contractors in that state. Employee rights is only one area where new business models and disruptive startups encounter issues with old regulations. Digital services could and should be global, but financial services and fintech are examples where regulation significantly restricts how and to whom services can be offered. In fintech, we see many restrictions, including what services are not allowed to users. Regulations are supposed to protect citizens, but they also safeguard companies using old models to continue business. Is that fair on people who ask for freedom, not protection? Regulation is one of the main reasons why fintech services are slow to acquire market share. It doesn’t just limit how services are offered; it also makes it more expensive to provide services. In the global sense, it is hard to understand why you can only use services in your own country. Why is it that you can travel to another country to get financial advisory services and make investments, but you cannot, in many cases, use those services online or talk on Zoom with your advisor in another country? There are many other examples of how startups and new business models collide with old regulations. And it is not always the regulations. For example, labor unions or incumbent companies push to introduce new laws and regulations to protect their position. Taxi companies, taxi driver unions and banks are famous for utilizing laws and their lobbying power against newcomers. None of them have a reputation as model citizens or focused on offering their customers the best service. In most cases, the arguments against newcomers are justified with good intentions such as protecting customers, employees and ensuring fair competition. It is never easy to say what is right and wrong, and the best way to protect someone. Still, it would be more honest to say that in most of these cases, the question is not really about the protection of customers, employees and competition, but about the fight between old and new models. Many people want to drive for Uber, and similar services, as independent contractors and have their freedom to do other things, too. Then some people like to have more permanent employment and get paid holidays. Many people would like to use new fintech services and global financial services, and then some people just want to walk to their local bank branch and send checks by mail. As a result, societies become fragmented. It is tough to have one model fit all, but regulation forces one model that everyone is made to follow. That’s OK and easy to understand if the objective is to protect all people. But if it concerns people who do not want that protection and it causes no harm to other people, it is harder to justify. Of course, there are always arguments about indirect impact, e.g. how the competitive environment is shaped. Let’s be honest; many of these questions are political. They are about conservatism versus the freedom of individuals and businesses. Some of them are also about negative and positive freedom models, i.e. whether a system allows something and offers equal opportunities to different parties. Anyway, a kind of reality in business is that the most efficient model will win eventually, assuming lawmakers don’t restrict people’s freedom by limiting the choice of services they are allowed to use. The article first appeared on Disruptive.Asia.  People are living and working more and more in digital environments. COVID-19 has accelerated the transition to more virtual and digital interactions. Security is a concern in many services. But part of the problem is that security experts, companies addressing customer concerns and even governments focus on negative messages and want to offer restrictions and hard to use tools instead of focusing on opportunities and making the internet a more trusted environment. The thinking is often too technical and theoretical, not based on human behavior or user experience. Trust is a fundamental basis for societies and businesses. Countries where people trust each other typically work better than countries with shallow trust. It is hard to make a country or city safer just by adding more police officers or restrictions. If business parties cannot trust each other, they just try to focus on short term quick wins and don’t want to create long term commitments and investments. We have the same situation in the digital environment, but many parties still believe that added restrictions, more policing tools, and trendy, trustless transaction solutions would make it better. We can see this on many levels. In many companies, security officers and experts tell us what must not be done, how risky everything is and creating all kinds of rules for the organization. Governments also sometimes adopt very simplified models to use. Some countries even restrict what people can see and do on the internet. But even the US and UK want to move to more populist models like forbidding end-to-end encryption in the fight against terrorism or protecting children. Of course, it is a totally unrealistic request and doesn’t do much to make the internet a safer or better place. We all know how complex it can be using digital banking apps, identification and signing services. These are usually built from a very technical perspective, making something technically bullet-proof. Still, they are not lazy-user-proof when users don’t use the service or forget the security recommendations while using the service. The Financial Times organized its annual European Financial Forum in early February, and one crucial topic was digital finance services. Several speakers emphasized digital trust as a critical component for developing digital services. Nowadays, many things are done online, with email and messaging services, video calls and digital signatures. If parties cannot trust each other, it is quite impossible to conduct digital business. Facebook deletes billions of fake profiles annually, we all get loads of suspicious emails daily, and companies create bots and fake profiles on LinkedIn just to generate contacts to sell more. Companies use solutions to secure communications and information sharing internally. Still, more and more business is being done across organizations, and most often, email, Zoom and WhatsApp are the typical tools, simply because they are the easiest to use. It is quite evident that better trust solutions are needed. But they should be built on natural human behavior and somehow generate trust built up over generations in societies and communities. Cryptography experts cannot create digital trust. Typically, trust is built up step by step with human interaction. You may be in the same class in school, study together at a university, work together, or live in the same neighbourhood or have the same hobbies. Or you know someone you trust, and they introduce you to someone else, and you immediately trust them by inference. Trust is not black and white. You build it over time, it depends on the context, and you can lose trust quickly. And trust is not based on a set of rules and restrictions; it is based primarily on positive experiences with someone. We are stepping into a new era of digital trust. Then pandemic has accelerated the need to do this. We need new solutions to build and manage digital trust, and they will need to include both social and technical innovations. And they will also need to work with our daily digital tools, like email, chat, video calls, and data sharing. As trust in society is based on positive experiences and opportunities, we need digital trust tools based on positive experiences, mutual learning and finding more opportunities. The article first appeared on Disruptive.Asia. 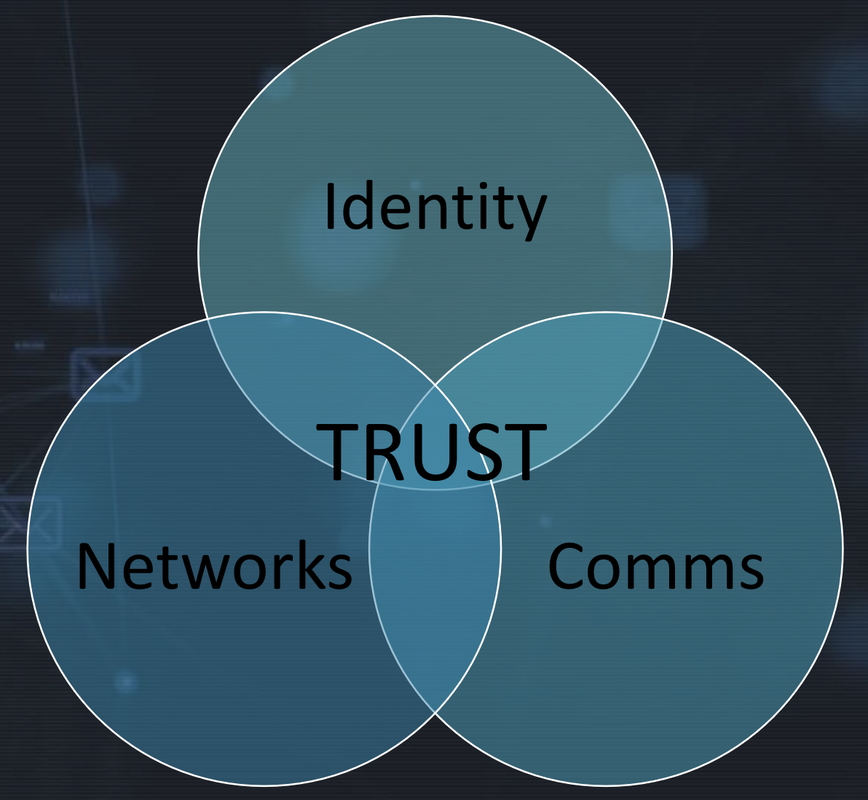 Companies have been collecting data for years. Useful data can offer competitive advantages and be the basis for many services and better customer experience. There have also been many companies that have wanted to become data aggregators, collecting and selling data. But the big data success stories are not in selling data. Sometimes data is almost a toxic asset. What can we learn from the ways that data has been best utilized and monetized? We now have the same question with personal data, and many parties want to repeat the same old mistakes. Fifteen years ago, in one of my earlier startups, we developed a marketing slogan: Data – the black gold of the 21st century. It was and is still a relevant comparison, but to make money from data is very different from the oil business. There you have separate business lines to drill and refine oil and then sell refined products. We can see something similar in the data business, but making big money in the value chain is very different in the oil and data business. Google, Facebook and Amazon are the superpowers of the data market. They primarily collect and then build services that utilize data. They might buy some third-party data, but it is not their primary way to get data, and they don’t actually sell data. The reputation of companies that focus on trading data is nowadays quite shaky. As a person who runs data operations for a Silicon Valley giant once said to me, they are more and more skeptical about buying data when they don’t know its sources, how accurate it is, how those companies that are selling it got hold of it and how they conduct their businesses. Don’t get me wrong, some companies make significant revenue by selling data, and some companies spend hundreds of millions buying data. But it hasn’t been an area to build unicorns and companies that shape the world as was expected maybe 10 or 15 years ago. Then there were a lot of expectations for data exchanges and other creative data trading business models. Today data is traded more like a commodity than a unique source of value add. Companies buy outside data to enrich their data and help their solutions to utilize data better. The real value is achieved when companies build solutions to use data in marketing, sales and operations. One could even claim, the winner doesn’t have the most data, but the best tools to utilize the data. Of course, the Internet giants have heaps of data. Still, banks, telecom carriers and retailers have lots too (and the opportunity to collect more), but they have generally been slow to utilize it. Those successful companies also offer the data’s value to their users, like Google search, maps and other services, and Amazon’s better customer experience. We are now seeing early days of personal data, i.e. how people can utilize their own data. Some initiatives and companies want to build solutions based on ideological views; people have moral rights to own and control their data. Those haven’t done too well; only a small set of people are interested in these ideological projects. Then there are those companies that want to help people collect their data and sell it. This has many practical challenges, including how to get a data market to work with enough demand and supply. Pricing is also a complex challenge, as are the associated terms and conditions, whether you sell your data for one purpose and how to track its use. It is not easy to get this personal data market working correctly. The user value promise is often disappointing, like being paid a few dollars monthly to watch ads. The most obvious option that has worked with the big data businesses for over ten years is forgotten. Why not offer people better tools to collect and utilize their data. When some companies want to help people to control and use their data by selling it, it is similar to recommending Google, Amazon and Facebook to sell all data they collect. Those companies have achieved their current position and power by having top tools to utilize the data they get. It is the same with individuals. If you want to empower them with their data, you need to offer the best tools to utilize that data personally. Utilizing personal data will include many concepts, and we don’t know them all yet. We need an open market to innovate and develop those tools. But it can have, for example, tools to plan better personal finance, find the best prices, manage better health and wellbeing, and get help in all kinds of daily needs and activities. The longer-term vision is to build personal AI that offers a dashboard to guide all daily activities. As with data businesses, personal data could also be enriched with external data sources. For example, public data like price comparison, traffic, public health and map data combined with personal data making it more powerful. Data model training for Machine Learning and AI improves when it can use data from many users. In many ways, the best way to utilize personal data is similar to what the leading data companies have done for years. But it seems that with a new business opportunity, many parties first go to very complex models, like justifying data with ideological thoughts or wanting to build a blockchain-based data exchange with digital rights management systems. Often the simplest and best solution is to copy one that has worked earlier elsewhere. The article first appeared on Disruptive.Asia.  Artificial Intelligence (AI) is popping up everywhere, at least in discussions. Intelligent systems are being used in many places, and they are becoming smarter. But the real bottleneck is not the intelligence or ‘brains’ of the systems; it’s that AI also needs ‘hands’ to do things. AI has become a very popular keyword over the last five years. Most company management groups and boards want to see some AI development in their organizations. Unfortunately, the reality, and actual use cases and expectations are not always in line. The biggest problem is not having smart enough machine learning (ML) or AI models to analyze data, handle tasks and make decisions. Let’s take a simplified AI task. A system collects data, analyzes the data, makes needed conclusions and decisions and sends the results for operative use. If a whole system is built to work around AI, like a self-driving car, the capability to analyze the data and make decisions can be the bottleneck. But most systems are different. We can take another example utilizing AI – automating insurance claim processing. We have the same phases, but data and interactions with other systems are much more complex:
In this example, we can see that the data analytics and decision-making is a small part of the overall process flow. There are many other parts, especially getting data from several sources, formatting the data, entering decision data to other systems and triggering actions in different systems. And what makes this even more complex is that typically the data is in many different formats and a part of the information is missing or is inaccurate (just think the claim form the policyholder fills and add attachments). Even the case of a data value being “null” needs to be handled, “null” is not “zero” and depending on the data set, it can have meaning or not. There are many handlers needed. One of my companies implemented this kind of system several years ago. Although it was quite a digitally advanced insurance company and environment (Scandinavia), there was still a lot of work to be done. A typical rule of thumb in the data business is that 60% to 80% of the work is to pre-process the data. This is reality when you try to implement AI in any enterprise with many existing systems, and some of them can be quite old-fashioned. Just think SAP, Netsuite and links to banking systems. We can even think of a more modern solution to get data from several wearable devices (Apple Watch, Fitbit, Withings, Garmin, Oura, etc.) to one place and bring it into a format that you could build ML/AI solutions on top. Even to collect all that data is not as simple as you would think, even when people talk about open APIs. APIs are still not so common, and while an API will be structured, the quality of data included can vary from one source to another. A term I have started to like is ‘AI hands’. It means solutions, how to get data collected from many old and new systems, format them in one place and then get the processing results to operative use in other systems. Companies often forget or ignore the development of ‘hands’ when it is fancier to talk about the latest innovations for the ‘brains’. As always, great thinking is rarely enough; you must collect and organize information first and then get things done based on your thoughts. In reality, these ‘hands’ are like software robots (RPA) that can work with different systems and devices. These include additional software components (e.g. OCR, NLP, data cleaning, APIs) to get the data and trigger actions (e.g. sending emails, start payment, start delivery). Other useful tools are webhooks that can trigger background tasks, for example, in the serverless environment and such as verifying data and running NLP. This means the capability to work with a vast number of different systems and formats. Open source is often the best way to support many kinds of needs from small and rare systems to major systems. There are many data formats and even unformatted data that no company can implement in their proprietary system. Here, open source is the only option. These ‘hands’ and ‘brains’ should be based on commonly used and widely available programming languages (e.g. Python) that help get ‘brains’ and ‘hands’ work together utilizing open source components. To get more AI and ML use, we need more and better ‘hands’ for AI. Management groups must also invest in these capabilities if they want to implement and utilize AI. And it is the same with consumer services, someone must offer the solutions where the data is available in a usable format, and there are tools to get results in real use. In last year’s Gartner Hype Cycle, many AI solutions were on the hype peak. AI ‘hands’ are needed to improve productivity. The article first appeared on Disruptive Asia.  Photo source: Wikipedia. Automation and digitization should increase the productivity of work. But productivity growth has been flat or declining in most developed countries during the past 20 years. This has been visible in countries where most jobs, and especially new jobs, are not in manufacturing, but in services and information work. So, it would be fair to assume that technology and digitization don’t help improve productivity. Henry Ford, Jeff Bezos and Larry Page didn’t win big because they optimized old operations; it’s because they created totally new operating models. Opportunity lies in developing new ways to do things, not optimizing old ones. World-famous economists, like Daron Acemoglu, Greg Mankiw and advisors of many governments, try to understand reasons for slower productivity growth. I won’t attempt to understand all the macro-economic factors, but to focus on small practical questions like what could be the bottlenecks with digitization and automation of information work. I wrote earlier about how we need real digitalization, not consulting projects. The problem of many automation and digitization projects is that they just try to optimize the existing processes and implement them in legacy IT systems. Both those processes and systems were developed before the current opportunities of digital services were readily available. The optimal model would be to build new processes with the latest technology focusing on the company’s real value to its customers. If you automate old processes that are unnecessary to offer customers value, it doesn’t improve productivity. That’s why genuinely digital companies like Amazon, Facebook, Google, Netflix, Alibaba and many startups win business from old companies. It takes quite a lot of courage from management and investors to disrupt old models instead of just trying to ‘optimize’ them. The reality is that to fine-tune old models with old IT could give you a small percentage improvement in productivity, but if you want to achieve much more, maybe 100 or 1,000 per cent gain, you must create new models to operate with the latest technology. I also wrote earlier about the trending low-code and citizen-development, and how it can rarely help implement robust well-planned solutions. This is another example, why automation of processes doesn’t always bring significant value when citizen-development is trending in automation. Suppose a company must create new models to operate so that customers can communicate digitally with it, and they digitize all internal and supplier interactions. In that case, it doesn’t work if each employee (i.e. citizen-developer) starts to automate their routines from the pre-digital era. It’s a sad fact that real automation also makes some work unnecessary. If you just let employees automate something they don’t like, it doesn’t make a company significantly more effective. Of course, by getting rid of boring routines, each individual and department can become more effective. But in reality, significant changes need much more fundamental changes. A record shop doesn’t become a new Spotify simply because employees automate some of their routine work. And a bricks-and-mortar retailer doesn’t become a new Amazon when employees automates their routines. Those companies need a new way to operate with new processes and new roles for their employees. Uncovering existing processes and automating them might bring some savings, but if you create new ways to operate based on new tools, you can create a whole new business. AI, digitization and automation (including RPA, robotic process automation) are at the heart of these changes. They are hype terms nowadays, and it is easy to make fun of them. Their reputations suffer if those technologies are not appropriately utilized; they become window-dressing, like lipstick on a pig. Suppose you put a little bit of AI and a little bit of automation on top of your old processes and systems. In that case, it is not making them more digital or intelligent, and it’s just adding one more layer of complexity and arguably, technical problems. Some companies would like to use machines to observe people and use AI to create automation to perform the same tasks. It sounds like an exciting tech vision, but it’s a strange idea that the optimal model for machines would be to copy how people have done something traditionally. Henry Ford didn’t build a car for everyone by asking old-style workshop car builders to automate some of their routines. Jeff Bezos didn’t digitalize retail by asking guys who receive telephone orders and fill paper order forms to use VoIP calls and scan order papers. Google founders didn’t revolutionize the online ad business by making an online copy of the yellow pages. They created new models from scratch, how they could offer the best value to their customers with the latest technology. But many companies still try to develop their operations by adding new tricks to old models. Automation, AI, and digitization will change most businesses, and they will significantly change the way information works. Improving existing processes is a multibillion-dollar opportunity, but creating new, more effective models to operate in hundreds of billions or trillions. Improvements bring short term wins; new operating and business models create companies that prevail in the future. All these require courage from management and investors. They must be brave enough to discard old models to operate and old systems. It is nice to promise each employee that nothing will change or promise two per cent stable growth to investors. Still, as we have seen in retail, this model leads to huge collapses, significantly when competitors change the business and market rules. Those leaders who want to create big successes should start to build their operations based on software robots, AI and digital processes, not just hope the old models can be done a little bit better. And they should start today. The article was first published on Disruptive Asia.  Photo Source: Wikipedia. A personal trainer gives you instructions on what to do at the gym. In most cases, she or he asks only basic things from you, like your target, to either lose weight or grow muscles, and maybe how often you have visited the gym before. A growing group of wellbeing consultants tell you, how to sleep, eat and work better. They might ask you to keep a sleep and food diary. These days, people have more and more wearable devices to measure daily activities, heartbeat, sleep, blood glucose and many other things. But there is still a very weak link between data, wellbeing and training services. However, this will change. I have read about sleep consultants whose primary task is to teach people to repeat some words when they try to sleep. They say it helps you to relax and sleep better. However, people nowadays have several devices that measure their sleep, heart rate when they go to sleep, sleep intervals, even body temperature and how tough their day has been. Wouldn’t it be better if those sleep consultants could utilize your data, and not only teach mantras? During the COVID lockdown, many fitness centers were closed. They started to offer online services, including virtual personal trainer sessions, online exercise classes and videos on how to train at home. But this is mainly one-way communication. The fitness center doesn’t take your data to create a more personalized plan for you. Why not? Technically it would be quite feasible, but they would have to develop new services for this model. Many customers would be ready to pay more for personal services than standard classes. The world is full of services to lose weight. People pay for online services to get instructions for daily eating and exercising. Some services help track your calories when you record your daily food entries. Most services are still elementary and don’t use data available from wearable devices. Nowadays, you can even track blood glucose in real-time. It would be quite useful with exercise, heart rate and sleep data for personal weight control services. The wearable market is increasing. The smartwatch market, in particular, is growing steadily, approximately 20% annually based on market research and is expected to reach almost $100 billion by 2027 from $150 billion this year. Smartwatches take market share from some other early devices that only measured steps and heart rate data, basic things. At the same time, new categories are growing, like smart rings (e.g. Oura) and blood glucose, metabolic health apps (e.g. Levels and Veri). Withingswas part of Nokia for some years, but Nokia sold it back to its founders and wrote it off, just when the market started to grow. It is a company that has a more extensive range of products from watches to digital blood pressure and under-mattress sleep tracking equipment. So, people are starting to gather a lot of personal data. But many people are still confused, how to utilize this data. Apple Health is a service that helps combine data from several devices if you have an iPhone. But it is probably the most confusing and worst UX product Apple has. As with business data, people need tools to utilize the data, and raw data is hard to understand. There are also other health data sources. DNA tests offer information on personal genetic profiles. Digital health care records are starting to become available in some countries. This data could also be combined with wearable data. This sounds like a perfect match. Wellbeing services should start to become more personal and based on real data, not only some standard instructions, because people are, in fact, individuals and different. Wearable devices provide more and more data points that are hard to interpret. Both those parties could improve their businesses if they learned to utilize the other party’s services better. How can this happen in practice? There are, at least, three ways to do this:
Any professional business consultant usually analyzes a company’s numbers and processes before starting to give instructions. It would be bizarre to have a consultant that would try to get a company to better health, without looking at its existing data. But in wellbeing consulting it is still very typical. This will change in the next few years, and we’ll see wellbeing services based on actual personal data. And this market will grow fast; people are ready to pay for better overall health and wellness. The article first appeared on Disruptive Asia.  When I started my career in the 1990s, I worked as a software developer for a company that produced slot machines and casino systems. One day, a group of consultants popped up to our department. They came to tell us that our software development was not very efficient and that with new visual tools, the same work could be achieved much more effectively. They promised to redesign software for our latest gaming platform in six months with a couple of developers. We had previously taken two years with almost 20 people to do the same thing. Our management bought their story. So, they started to rewrite the software, and from then on, we all had to adapt to drag-and-drop visual state-machine development tools. The same is happening again. Low-code and citizen-development are trending again, and companies are actively selling their expensive tools allowing anyone to design software or automate tasks. Why have costly developers when you can teach your employees to manage their daily needs with simple drag-and-drop tools? The whole software industry will be changed again! Office work automation (e.g. RPA tools) is one fashionable area citizen-developers have taken on. So, too, with data applications. Why have expensive data scientists when you can just offer low-code tools to anyone to get information and insight from raw data? I have even heard of those same low-code tools enabling individuals to make apps using their personal health data. Sounds nice? Three months later, those consultants came back to us. They told us it didn’t make sense to redevelop the whole gaming platform software, but they could create a smaller piece to prove their case. So, it was agreed they would only develop new software with their model and tool in small components, starting with a device that recognized coins when the players entered them. But is it so simple? Why are the world’s leading software companies in Silicon Valley paying $250,000 annually for good developers, if they can just take random guys from the streets (or at least offices) and get them to make software with low-code tools? Or why complain about a shortage of data scientists, if you can get any office assistant to find relevance from data with low-code tools. Two more months (total time now five months) and the consultants came back to us. This time, they told it didn’t make sense so they would rewrite the code we had already done. They could write a manual on designing better quality software, and they could also sell their design tool to us so that we could use it to improve our software planning. Some people build their own home, and others use ready-made design drawings. But would you like to go to a skyscraper or a bridge designed by a ‘citizen civil engineer’? Or would you like to take citizen-pilot flight with an automated aircraft? Why is it necessary to have more expensive professional pilots? I don’t mean we should have official accreditation to be a software developer, but it’s a fact that the most complex systems in the world nowadays are built with software. It is not simple to build complex critical systems. It is much more complicated than designing a skyscraper or a bridge. For construction, you have precise formulas to make calculations, but many structures of software solutions are so complex that you cannot have formulas or simple models to prove that they work. I have personally seen people with no experience or education, trying to understand how to develop software, especially robust software. It doesn’t work correctly; a study shows eleven of twelve citizen-developer projects fail. There are tasks people can program easily. Some people make Excel macros for their own purposes. People make some simple tools to help them in daily tasks; they know how to use them, with no need to handle wrong data entries or particular situations. At the same time, it is not ideal to leave more complex software development to citizen-developers with these simplified tools. It is also good to be clear with definitions. Sometimes low-code marketing uses examples, like design tools, that need no code at all. Low-code is a software development approach that requires little or simplified coding to build applications and processes. So, a drag-and-drop graphics design tool for end-users is not a low-code development tool until you want to convince your audience that it as a great example of low-code. I was just listening to an organization that has invested in citizen-development tools and used hundreds of hours to teach thousands of their employees how to use these tools. But they can still only do basic things. The management admitted, they would not let them make any mission-critical or important solutions and processes or implement more complex software. Finally, after six months in my early career case, the consultants could implement no software with their visual tool. They came to us with a manual for better coding and organized a half-day workshop. To be honest, after all these years, I don’t remember too much from that session, but one of their claims was that visual tools are better than software code, because people are naturally visual. Our developers disagreed with them because they didn’t feel these visual tools worked for serious programming needs. After the workshop, we never heard from those consultants, and we continued to make machines with professional programming languages. Those consultants were paid for those six months and their design tool, then they found the next customer (victim). The same is going on again; companies are buying software licenses and training to get all their people to make software. Don’t get me wrong; I believe software development tools and methods are developing, and many tools can help. But it is crucial to understand the difference between personal tools to automate something or make Excel macros and making reliable software that can run many essential systems and processes. The reality is the world needs more professional software developers and more reliable software. We must not mix professional software development and its tools. With some simplified tools, every office worker can make some macros or automate their own simple tasks; they are totally different domains. The article first appeared on Disruptive Asia.  This is normally the time to make predictions for the coming year. Typically, the focus is on tech and business trends and evaluate which ones could get next year’s timing right. This time it’s different. In 2020 the pandemic was a disruptor of normal trends. It stopped some businesses, changed some and accelerated others. So, what we can expect to see when vaccines hopefully turn the tide of the pandemic? If we briefly summarize 2020, it accelerated digital businesses by a few years, stopped travel and hospitality businesses, moved many activities from bricks and mortar to online and taught people to use many new tech tools. In 2021 the questions are, which of these trends will continue, which will turn back time to pre-pandemic and which businesses have changed forever. One or two years won’t change human beings fundamentally. People can learn to use new services and products, but basic needs don’t change. Let’s take, for example, how people have adapted to food delivery services, but they still want to meet other human beings. People also look for easy solutions but usually hesitate to do things they don’t understand or haven’t tested. But home delivery and Zoom meetings, because they had to be adopted, became everyday options, that we quickly learnt to use effectively. So, what’s the outlook for 2021? We must think about the things people have learned in 2020 and also what they missed in 2020. Then we must also consider which technologies and services took a leap in 2020. We can also evaluate, which trends started before the pandemic, and those that the pandemic has accelerated. Based on this, we can assess a little more accurately what we can expect to see. Digital services are helping people in many situations. Virtual meetings help us save time and money. Digital signatures make it easier to handle agreements and use legal services. Home delivery makes grocery shopping more straightforward and faster. Sometimes it is more effective to work from home. These have been obvious changes in 2020, but they are still good examples of trends that will continue after the pandemic. Airlines, hotels, restaurants and many other hospitality services took quite a beating in 2020. Many people have changed their views on travel and eating out, and are questioning if they need to take so many flights in future. This part is probably much more complicated. People still want to see new places, see other people, and break from daily routines and environment. But at the same time, many businesses are probably having second thoughts on the value of business travel and physical meetings. People now see the value of physical meetings and hospitality services in a new light, having lived without them for so long. People have also noticed they can work just as effectively from home or remote places. Nevertheless, data indicates that flight bookings for late 2021 are strong and that new business models, like monthly subscription for flights, are emerging. Retail businesses have suffered most from lockdowns and restrictions. Many retailers, even well-known, long-established department stores and chains, are closing down. But it would be a mistake to think the pandemic has been the only reason for this. Bricks and mortar retail has been in trouble for years, and surprisingly, why it has taken such a long time for some customers to adopt online shopping and use home delivery services. The COVID situation has not only impacted consumer businesses. B2B business has also changed. We haven’t had trade shows, conferences and meetups to find new products, services and contacts. This has pushed the adoption of ‘self-service’ online sales channels, but at the same time, traditional ’face-to-face’ sales are vital for most B2B businesses. There is no doubt that B2B companies have also suffered, and there will certainly be bankruptcies after the pandemic when companies are forced to take a reality check. Based on the above, here are some of my predictions for 2021:
The article first appeared on Disruptive Asia.  |
AboutEst. 2009 Grow VC Group is building truly global digital businesses. The focus is especially on digitization, data and fintech services. We have very hands-on approach to build businesses and we always want to make them global, scale-up and have the real entrepreneurial spirit. Download
Research Report 1/2018: Distributed Technologies - Changing Finance and the Internet Research Report 1/2017: Machines, Asia And Fintech: Rise of Globalization and Protectionism as a Consequence Fintech Hybrid Finance Whitepaper Fintech And Digital Finance Insight & Vision Whitepaper Learn More About Our Companies: Archives
January 2023
Categories |

 RSS Feed
RSS Feed
|
Digital Intelligence Globally
|

© 2009-2023 Grow VC Operations Ltd. All Rights Reserved.
|