|
It’s not expensive to buy a spy, according to a recent article. You can ‘buy’ a spy for $10,000 a year, or in more significant cases, you may need to pay $40,000 to $70,000, especially if the spy takes a considerable risk. There are other motives for people wanting to sell or give information, not just for military and international politics secrets. Human beings are a significant security risk for businesses. Can we do something to improve this weakest link? Colonel Vladimir Vetrov was one of the most important spies during the cold war. He worked for the KGB and leaked more than 3,000 pages of documents to French intelligence, including the names of more than 400 Soviet operating agents. He operated from 1981-82, and it is said his information went direct to President Reagan. He played an essential role in exposing weaknesses in the Soviet Union, its dependence on stealing western technology and how an accelerating arms race was driving it to collapse. However, it seems Colonel Vetrov didn’t do this for the money. He received some small gifts that he gave to his mistress, but nothing significant. He was more embittered with his career development at the KGB and also frustrated by the Soviet system. Several studies and cases demonstrate that embitterment is often a more important motive for spies to leak information than simple greed. Edward Snowden leaked highly classified information. His motivation was not clear, and now that he is now in Russia, he has indicated he was unhappy that the US authorities spied on its own people. Wikileaks also received leaked information from other people working in governmental agencies. Governments and enterprises spend a lot of money developing better solutions for physical and cybersecurity that are becoming increasingly significant. And these investments are definitely needed. But at the same time, it is important to remember; it’s people that leak information and create holes in even the most sophisticated systems. I have personally seen cases of spying or information leaking during my career. Once, a person at a customer leaked information from our competitors and how some people in the organization worked with the other vendors because he was not happy about his position. In another case, a company warned us that a cleaner in our project office had collected documents and photos from our bid documents. In one extreme case, someone set off a fire alarm in an office, and several laptops of a new project team went missing. All these are old cases. The question is, who can you trust? It is not an easy question to answer, and it is not black and white. Even the most loyal person can change and start to leak information. We could also say that no one is totally reliable; most people reveal information at some point, either intentionally or unintentionally. One solution is to keep people loyal. A good salary helps, but even more important is to make people feel they are being treated fairly. Companies try to identify problems to keep their employees loyal and reliable, but it is rarely enough. That raises the question as to what information is relevant. Many companies hide information that is not very relevant to anyone, competitors or customers. And those parties can usually get that information quite easily, so it is not a good investment to try to hide it at a high cost. It can also increase the risks of leaks if employees feel that irrelevant information is being classified as secret. There are technology solutions to avoid, identify and reveal spying and information leaks. For example, one old method is to make each copy of the information (e.g. a document) unique in order to identify whose document was leaked. It is also important to track who has copied some confidential information or had access to a system. There are other solutions, e.g. identifying unusual behavior, setting test traps or monitoring communications. It doesn’t make any sense for companies to take similar measures as critical governmental agencies if it creates ‘bad spirit’ in the organization. One big risk area nowadays is employees using their own devices and personal communication tools. Several simple solutions make sense. Suppose sensitive discussions between business partners preparing a bid, between a company and its law firm, or amongst board members take place via a messaging app, a Facebook group or another similar service. In that case, it increases the risk of inadvertently sharing information with other parties. Sometimes it can happen accidentally, especially when people are handling multiple groups and discussions simultaneously. It is not realistic in many of these cases to force people to use higher security tools which can be challenging to enforce between organizations. Most security tools have been designed for use within an organization. Technology is not the only solution to stop people from leaking confidential information. But technology can help to avoid accidental sharing, easy leaking and identify the sources of leaks. These solutions must be easy to use, and they must work with commercial off-the-shelf (COTS) technologies and services. They can help keep information in closed groups, prevent direct sharing, and identify if someone has shared confidential information. Security and trust in people is not black or white, more like shades of grey. There will always be people who want to spy and leak information, whatever it takes. But for the majority, it probably helps to have clear rules, better tools and increase the risk of getting caught. Any company that invests in building security in its physical and cyber environments must also think about building and monitoring trust with its people.  We are all probably skeptical about people who tell us what we should do because they think it’s what is best for us. A good example is adults telling kids and teenagers what to do and not to do to protect them. Apple and Google are doing something similar with privacy. They want to be consumers’ parent to protect their privacy, but they want to keep control. Do consumers really want this, or would they like to control what to do with and where to use their own data? Here lies an opportunity for a new data business. Apple is introducing new models in the latest iOS versions for users to control the trackers of mobile apps. Basically, a user must allow apps to follow them around the web, collect data and target other apps. Not surprisingly, there are estimates that around 70% of people, if asked, would not allow tracking of this type so that Apple may be onto something. However, this also increases Apple’s control of the ecosystem and makes it even more a closed-garden system by giving Apple control over what app vendors can do and how they do it. This would have an impact on other companies like Facebook and Tencent, which operate online advertising. Facebook has already warned, this would affect its revenue. Tencent and other Chinese mobile internet companies have developed workarounds for the model. Google’s Chrome will shortly stop supporting third-party cookies, making it harder to track users on the web. Simultaneously, Google is preparing new solutions to track the browsing history and profile and segment users, enabling advertisers to target ads better. This is coming from Google’s Privacy Sandbox project and gives Google a more critical role in the advertising ecosystem, making it harder for smaller ad companies and advertisers to work independently. Privacy and user tracking resemble something from the ‘wild west’. It becomes more complex when a few companies can control a significant part of the internet and mobile ecosystems. This may be specifically about web tracking and ad targeting, but Apple’s Health app collects data from wearable apps and enables downloading of health records, and Google Fit aims to do the same. All this opens the opportunity for a new unholy alliance between consumers and enterprises. Consumers could share their profiles direct with businesses and bypass the internet companies if they could see concrete benefits. This is not a new idea, but it needs easy solutions to become a reality. It is unlikely consumers will do something just for better privacy; they will want to see those benefits quickly. Let’s take a few examples of what this business and consumer cooperation could mean:
These are a few examples of how users can have a direct data relationship without the internet and mobile giants trying to control it. But consumers will need tools to collect their data and share profiles (not raw data). It can’t be something each individual negotiates with enterprises who would dominate, and consumers wouldn’t know the right price to demand. Consumers need weapons (i.e. tools and models) to do this properly. Ideally, this would be an open ecosystem with open source tools, open APIs in an open environment where different parties and developers could provide the means for consumers to keep their data. All this opens the door to new technology and companies to offer solutions for consumers and enterprises. Could this be the most significant change in the data business since the early days of the internet? Regulators could also accelerate this development by introducing new privacy rules, giving more power to consumers to control their data and restricting the internet giants’ dominating market position. Current privacy and data discussions and developments can confusing. Even though parties exist that want to protect consumers, they often add restrictions that make their lives more complex, particularly if they continuously need to click approvals. At the same time, data analytics offer more opportunities to consumers and businesses alike to better utilize data for better services, better prices, and make lives easier. The motives of some ‘protectors’ are not very clear and maybe not as ‘innocent’ or as ‘honorable’ as they might appear. There also lies the possibility of ‘data dominance’ simply moving from one actor to another. Long term solutions for data and privacy cannot be based on the controls and restrictions of a few big companies. Consumers must be able to control and utilize their data. All kinds of companies must also be able to use data if they can offer value to consumers. Otherwise, not only advertising but many other areas, including health and finance services, could also end up in the control of the internet giants. The article was first published on Disruptive.Asia. 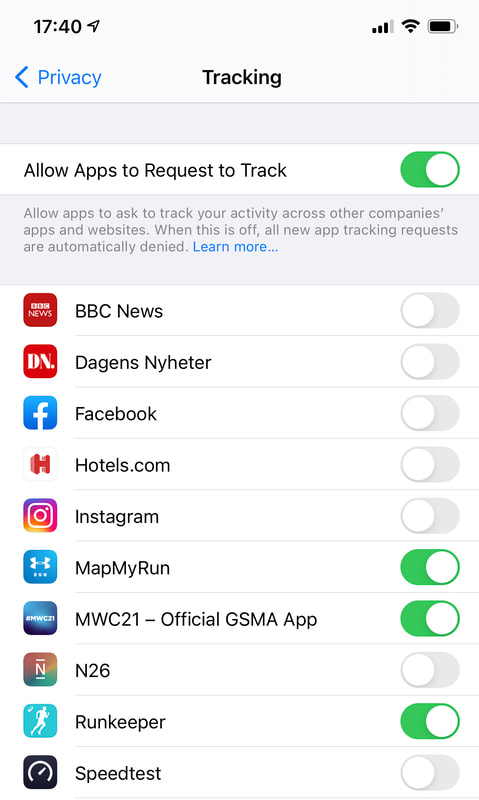 Data is the basis for many operations, but it doesn’t mean data is always reliable. Things can get complicated when you don’t know which data source is reliable and which is not. But we must use data all the time. Sometimes it is possible to increase the accuracy, but the more meaningful solution is to build a software layer to correct data before using it. I earlier wrote about known and unknown things and data points. The reality is even more complex. We know some data is relevant, and it is available, but we don’t always know how reliable it is. We all know about opinion polls and their error margins. It is just one example, but uncertainty is linked to all data sources and models that utilize data. In aeroplanes or nuclear power stations, the core systems do not necessarily trust individual sensors or data sources. There can be many reasons why a particular sensor gives incorrect data. For example, a pitot tube that measures an aircraft’s airspeed can transmit incorrect information if frozen, which has caused several plane crashes. Today, a plane typically has several pitot tubes, and the software tries to draw conclusions and give pilots warnings if one or more give inconsistent readings. Sometimes the situation is more demanding when it is difficult, even impossible, to know if data sources and sensors give accurate data and how large the error margin is. Examples of this are wearable devices. They can measure your exercise patterns, sleep, and body functions like heart rate, temperature or blood pressure. These devices are calibrated using higher accuracy devices during development. But it is still hard to say how accurate they are for different people in different situations. For example, even with top-level research instruments, it is not easy to measure how much light sleep, REM, and deep sleep a person has at night. We might also have a situation where we have many sensors, but some data might be missing. It is a complex task to combine data from different sources, and it is also tricky to know if available data makes any sense combined. This can occur when having many IoT sensors or an organization’s internal data from multiple sources to measure processes or even financials. It is often said that intelligence makes up only 20% of AI implementations, and the rest is getting data, combining it and correcting errors. This layer is often underestimated. I have seen projects where 95% of the data is inaccurate, incorrect, or missing data points. There are several ways to increase the accuracy of data, for example:
These layers combine, correct and smartly use data and become more important as we get more data sources. One could even say it is pretty simple to create AI models if someone has developed this layer to make reliable data available. It is often said that IoT business is not really to sell sensor hardware but to manage data, but what is ignored many times is the critical question of getting reliable data. It is not easy to make these layers that combine data because each source is different, and it can also require an understanding of the data to be able to analyze and integrate data sources. It is possible to make general models and tools for this, but they often need tailoring for the different data sources and combinations of data sources. With AI’s hands, these smart data combining models and layers become a vital part of the data and AI business. Data is valuable only if it is reliable. We can trust AI only if it can use correct data. The reality is that no data source is 100% reliable, so we need intelligence, how to correctly and optimally use data sources. The article was originally published on Disruptive.Asia.  Photo Source: Wikipedia, automatic landing system. |
AboutEst. 2009 Grow VC Group is building truly global digital businesses. The focus is especially on digitization, data and fintech services. We have very hands-on approach to build businesses and we always want to make them global, scale-up and have the real entrepreneurial spirit. Download
Research Report 1/2018: Distributed Technologies - Changing Finance and the Internet Research Report 1/2017: Machines, Asia And Fintech: Rise of Globalization and Protectionism as a Consequence Fintech Hybrid Finance Whitepaper Fintech And Digital Finance Insight & Vision Whitepaper Learn More About Our Companies: Archives
January 2023
Categories |

 RSS Feed
RSS Feed
|
Digital Intelligence Globally
|

© 2009-2023 Grow VC Operations Ltd. All Rights Reserved.
|