|
It’s often said people don’t appreciate things they can get for free. Another way of looking at this is that it is difficult to determine its value if you don’t pay for something. With the cost of sending emails or getting contacts in social media virtually zero, does it mean it is harder to get value from them? Should we start to pay for contacts and messages? Do you remember the time when there was just a landline phone at home? Or when you received letters through the mail? When your phone was ringing, someone definitely answered the call and actually took the call seriously. When you got a letter with your name and stamp on the envelope, it was something you wanted to open and read. Now you get robocalls that use VoIP, making them really cheap. You get a lot of emails, most of which you don’t even open or read. How about social network contacts? You can send LinkedIn or Facebook invitations to almost anyone, and many people accept invitations from people they don’t know. One could say this has made people better connected and made the world more democratic. Earlier you could have tried to get into an exclusive club and use your contacts to help to arrange an important new introduction. But how much value do your social media contacts actually produce? Not much, and less each day, I would argue. In an earlier article, I wrote how many social networks had become spamming networks. It’s great that prices go down and more people get access to networks and opportunities. But this also has its side effects. Everything becomes too crowded, and everyone tries to use them for their own purposes. When connections, communications and transactions have minimal or zero cost, people don’t consider using them properly. It leads to a situation where those networks and tools offer less value. It’s a bit like a government starting to print a lot of money. The money loses value, and then you can’t afford to buy things with it. Would this change, if we had to pay for contacts, messages and transactions? Most probably. It doesn’t mean they should be so expensive that it starts to limit who can use the tools significantly, but it would make people think about what they are doing. Maybe people would start to appreciate more the contacts they have and the messages they receive. It doesn’t really matter to the users what technology makes transactions payable, but the user experience matters. To get this to work, very simple micro-payments are needed. At the moment, it looks like blockchain and tokens are the strongest candidates to change business models of messaging and social networking services. This is something that has been talked about since the 2017 ICO boom. The missing piece has been workable, effective end-user services, not just concept ideas. It is not realistic to think that totally new communications tools would replace the existing ones. New solutions to better manage contacts and messages should work, for example, with the existing email and messaging services. One can also claim that people are not ready to pay for these commodities they have always had for free. And not all people will be ready to do it immediately, but people are happy to pay for things that make their life better, help them with daily tasks and give them greater status. There are many signs that people are now looking for better privacy and control of their data and activities, and security is also becoming more important. People have always been willing to pay for exclusive clubs. They have been willing to pay for dinners with top politicians and celebrities. If someone you don’t know wanted to message you, you would be more interested in looking at the message if you know they had paid for it, and it was not one of the thousands of ‘free’ messages. If a user only accepted ‘paid’ messages, it would cut down the level of spam, too. Good contacts and important messages are premia, not commodities. We will soon see services where people pay for messages, not for all messages, but some of them, e.g. to reach new contacts. We will also start to see services where people will have to pay for contacts, and they will have to give serious thought to which contacts they really want to invest in. But these services will need to offer the same usability as chatting, social media and email today. This concept could become one of the first big use cases for blockchain and tokens. The article first appeared on Disruptive.Asia.  Private club. (Photo: Wikipedia) Data and computing have moved to a centralized model during the last decade when many services have gone to the cloud. This trend continues, and we will see many more companies go to the cloud. At the same time, we are starting to see a new trend toward more decentralized models. But it is still a combination of different things. It might look like fuzzy development, but it really happens. There are several reasons why we will see more distributed models for data and processing overall in the future. We can divide them into three main categories:
I have often said it is not hard to predict the future, but it is hard to know the right timing. It is also the case for this development. There are so many good reasons to have more distributed services that it will happen. But it is not easy to say how it will happen, where it will really take off and how long it will take. We now see several technologies that make this development real. First, we have Edge that comes into effect with 5G networks. Edge keeps data and processing closer to actual users. The challenge – are network vendors and telecom carriers the right parties to deliver these solutions when Internet giants like cloud vendors now dominate services and service development? Secondly, we have blockchain, distributed ledger and token models. These are all developing rapidly, but they also have their challenges. It is not easy to say which technology can survive the longest. In this case, it is not only the technology but also the transaction data in those chains that must survive, making it difficult to make decisions about a particular technology. At the same time, these will challenge centralized platforms, as they offer totally new ways to distribute and monetize applications and data. Thirdly, decentralized solutions can be implemented inside existing cloud solutions. We, of course, have regional cloud instances, but clouds enable other ways to decentralize services. For example, each user can have their own cloud services to use their data and run their own applications. Then, for example, with token-based charging models, they can also pay for using apps locally. Of those three technologies, Edge has many challenges as it needs totally new infrastructure and applications to take advantage of it. It is currently much easier to make decentralized services by utilizing the current cloud infrastructure. But longer-term solutions can be another story. Technology disruption often attracts new companies that disrupt business. For example, Amazon and Google are tied to centralized models. Can they adapt when decentralization starts to happen and other vendors offer the latest solutions? We will likely see two different development tracks for decentralized solutions. The first one being distributed and decentralized applications. This starts with the existing infrastructure and builds distributed solutions, such as a user’s own data cloud and application service. This track already has applications. Then we have the second track to develop a more decentralized data and processing infrastructure. This will take a longer time, but it can fundamentally change the structure of the Internet. We are definitely moving to more distributed services. Thousands of startups are already developing services, data models and applications. Big technology vendors are investing in Edge type models, millions of people are trading cryptos, and forward-looking investors, like Andreessen Horowitz, are making big investments. At the same time, regulations are putting pressure on making new data models. The exciting part will be to see how it will happen, and the parties that make it happen will be the big winners. The article first appeared on Disruptive.Asia. 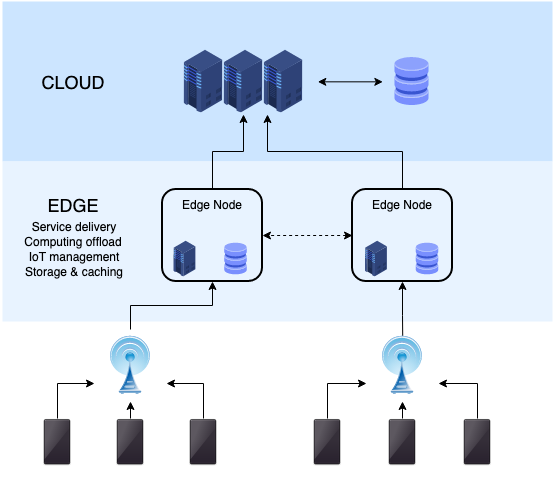 Some of you might remember when home and personal computers were emerging in the 1980s. Many different companies made their own devices, like Commodore 64, Apple II, Spectravideo 328, Sinclair ZX80 and Atari. Then some manufacturers agreed on standards like MSX that never actually became globally significant. But then personal computers (PCs), with PC-DOS and MS-DOS, started to occupy offices and then homes, and Apple created the only other option. We now have a similar situation with wearable devices. In the 1980s, most computer manufacturers had their own operating systems and a small range of programs. Early adopters had those devices more as a hobby than to really utilize them. There were all those stories about use cases like recipe databases or calculating your taxes, but only if you code your own program. Many users actually did write their own programs and shared them with other users. As a teenager, I tried to explain to my father the value of owning a computer. It was not an easy task when he didn’t feel that coding your own games or graphics programs were valuable reasons to have the device. How is this relevant for wearables? We have now more and more wearable device manufacturers that offer their devices with their own proprietary functionality, data models and applications. Many users are still early adopters like biohackers and health enthusiasts that explore ways to utilize the data. Most users can understand a couple of data points like average heart rate and the number of daily steps. Those are a good start to observe and improve personal health, but it is a small part of the data and the opportunities these devices can offer. Some additional data points like Heart Rate Variability (HRV) and different sleep types (deep, REM and light) are much harder to interpret and utilize daily. One could ask, as my father did if it makes sense to pay $400 for a device to see heart rate and daily steps. Or why pay over $100 monthly subscription for a glucose measurement device or more expensive shoes to measure cadence, stride length and foot strike angle. For many people, use cases like a device letting you know when to go to sleep sound as naive as a recipe database. Each manufacturer also has its own scores. For example, sleep and readiness scores from one device are very different to another device, and there is no easy way to combine data from different devices properly. Or you can combine some data, for example, to Apple Health, but it then contains a lot of data points that are even more confusing than data in the device’s own apps. What changed the computer market? How did they start to become more useful? It happened when software packages started to appear. A couple of operating systems, from Microsoft and Apple, started to dominate, and both systems had enough software being generated by third parties. This evolved into the software industry, making software for personal computers. Actually, we saw a similar development in mobile phones. The mobile application business started to grow only when we got from proprietary systems to two main operating systems, iOS and Android, that enabled application stores to make a business out of applications. As we have discovered, wearables are not only for data; they can also be accessories and fashion items. A luxury brand could launch its own smartwatch or ring, but luxury brands are not really high tech or data companies. And it is not very convenient for users that each watch, ring, sensor, pair of shoes or jacket offers its proprietary data format and application. It would also be much better for luxury goods companies to have some common data models and ecosystems. The real utilization and software market for wearable and wellness data can emerge only when we get data from different devices to a compatible format. When we have two or three environments, software developers can make better software and applications to utilize data to help people in their daily lives. We cannot expect each individual to start to interpret all kinds of health data points and try to Google instructions and what to do based on them. A special requirement with wellness and health data is that it is even more sensitive than data for many other purposes, and privacy is crucial. It has been said that the IoT market won’t really be a hardware business but a data and software business. Wearables will basically be sensors to collect data. Some sensors could be branded devices, others white label components in clothes, shoes or accessories. But the real utilization of data needs environments where the user can combine the data, and software can be offered to users to help them live better and healthier lives. The real business and value of wellness data will be software and applications that can combine all kinds of wearable data with other data sources.  We have now waited a decade for the big wave of fintech company launches. People are frustrated with traditional banks and their services. Neobanks grow, but they are still tiny compared to conventional banks. Crowdfunding and P2P lending were going to change the market too, but they are still relatively marginal. Crypto finance grows, but is it a finance model, asset class or speculation? Stripe and Coinbase have been the big success stories in fintech with huge valuations. On the other hand, the collapse of Greensill Capital in the UK was seen as a setback for fintech. These examples just demonstrate how broad the fintech sector is. In reality, Greensill had nothing to do with fintech, but it wanted to attach that attractive tagline to itself. Greensill was a supply-chain finance service and failed due to its risk management. There are dozens of digital-only neobanks in the world. It is estimated they have approximately 40 million customers. This is still a very small number, but the valuations of the neobanks have grown rapidly. According to Accenture, a neobank loses on average $11 for each customer, i.e. costs versus returns. They still struggle to find a profitable business model. Basic bank accounts are not profit centers. Lending, investment, and niche services (e.g. business banking, special customer groups) are more common areas to make a profit. Still, they are very different from basic digital accounts, and their risk management is markedly different. Some neobanks such as N26, WeBank and Monzo, offer the full-stack, i.e. they have a banking license and have their front and back-end operations. Then there are neobanks, like Revolut and Chime, that have no banking license and offer a front end but use legacy bank licenses and back ends. The banking license is the complex part if we think of scalability and global growth. It is a significant investment to get a banking license in every new country. Ten years ago, we had a lot of expectations with crowdfunding and peer-to-peer lending. Those services have grown but not yet come to the mainstream. The P2P lending market is growing approximately 25% per year, but a significant part of the money comes from financial institutions that use those services as a customer interface. One of the biggest P2P lending success stories, LendingClub, acquired a bank last year and decided to close down its P2P lending platform. Crowdfunding has had many models. Startup equity crowdfunding focuses primarily on startup funding and pre-order models, like Kickstarter, that help sell new products before they are available. There are also other models that sell investment fractions in real estate, art and other assets. Kickstarter has been an important test market for new consumer products, but otherwise, these models have suffered from regulatory restrictions and haven’t come to the mainstream. In equity startup crowdfunding, the UK has been the leading country. However, its most significant services Crowdcube and Seedrs, are still small businesses, and they tried to merge, but the competition regulator blocked the merger. Cryptos hit new records, especially with bitcoin’s growing value. NFT’s have become popular. It is still hard to say what this means for blockchain-based distributed finance services. Many parties still see cryptos as more digital commodities and NFT’s like digital asset certificates, but not yet as challengers to the whole traditional finance system. Coinbase, which managed a successful IPO, is still more like a conventional trading service for ‘crypto assets’, not, e.g. a distributed finance service itself. If cryptos become more accepted and feasible with daily payments, and NFT’s make asset certificates and transactions digital, it changes the everyday use of those. Could they better enable crowdfunding and P2P finance? Some experts see it as the case, but it is still hard to say when the last decade has shown those models are not easy to get working. It is not only about technology but really about getting a market to work with enough supply and demand. And regulators also have a significant impact on the market. In some countries, we might see more approaches like government-run digital currencies than genuine cryptos. Then we have the fundamental question about the banking system. Banks are not just there to offer accounts, payment cards and to lend money; they also have an essential role with the central banks to issue money and keep the economy running. Some people criticize that system and would like to see the power of banks disappear. In reality, it is not so simple, and governments prefer to keep their control over their finance systems. The pandemic time has also reminded us of the value of government stimulus activities. Some banks are starting to accept cryptos, and one of the leading VC’s, Andreessen Horowitz, is planning a $1 billion fund for cryptos and blockchain, and it’s third in the sector. We can assume blockchain and distributed solutions will change and digitize daily assets and transactions. The first phase will probably be in digitization, not changing the fundamentals of the finance and banking system. But it is still hard to say how they can change the finance sector and services in the long run. The article first appeared on Disruptive.Asia.  There’s been a growing trend to get rid of middle management, which coincides with the belief that AI and software robots can automate work done by human professionals. So, fewer managers are needed and, therefore, less human resources management. But when we have more machines to work, they also need to be managed. Consequently, we probably need digital counterparts of middle management and human resources. A recent podcast has an interesting discussion about micro tasks to analyze data and make micro-predictions, such as analysing a specific dataset from one source and trying to conclude something from it. This analysis doesn’t try to understand or optimize a more significant problem or task. It just focuses on one specific part. A more extensive system can have dozens of components like that. Then there is another layer to combine output from those micro-tasks. It can then combine the output and conclusions from several micro-AI modules—individual micro AI’s focus to model and explain one specific data set. For example, running shoe data (yes, there are already running shoes that collect all kinds of data) of your cadence, stride length, ground contact time and foot strike angle to optimize your running speed. When you think about your running performance as a whole, this is only one part. You must also think about heart rate, energy levels (blood glucose), readiness (have you slept enough) and many other things. But it would be too complex to build one huge AI to optimize all this data, and it is better to have modules for each need and then another layer to combine all this. It is the same with software robots. One robot can transfer inventory numbers at the end of the month from SAP to your accounting system. To produce monthly financial statements and reports is much more work than simply compiling those inventory numbers. Other robots could perform the individual tasks and some higher-level robots to put all this information together. This is nothing new as such. Modularity has been an essential principle in designing software for decades. With AI and automation, we often talk about extensive and complex solutions linked to many tasks and systems around an enterprise. When these are also relatively new areas, each company and project usually try to build large systems that try to make a perfect solution for a significant process. When we have these micro modules to handle a specific need, we can then develop design principles. Not to implement from scratch, but to find the best components to do micro-tasks, optimize their use and then get them to work together. It is a kind of HR and management function. You must find the best resources to do things you need, and then you must manage them. But these management layers are digital, i.e., algorithms that choose the best algorithm for each micro-need and optimally use them. Algorithms manage algorithms. This also changes the ecosystem and business models for AI and automation. You have, for example, the following business areas:
Sometimes it is good to compare technology and machines to models of how human beings perform jobs. Especially when AI and automation are to perform tasks that humans have previously done. People have anyway used centuries to develop models, how to organize tasks in organizations. It doesn’t mean we can or should copy the same models to machines, but it can give us ideas on how best to use machines. There are reasons why people specialize in certain areas, how different professionals work together and how the management layer must optimize resources. We need to solve similar issues when designing, using, and managing algorithms, machines, and digital processes. The article first appeared on Disruptive.Asia.  Photo source: Wikipedia.
Numerous cities around the world want to become ‘smart’ cities. One main objective of smart cities is to collect data to improve and develop services. As a result, many vendors are also keen to get to the smart city business. These projects are network, infrastructure and big data intensive. So how does this benefit ordinary people? Any value to individuals and their privacy seem to have a lower priority, although the ultimate target should surely be to improve the lives of residents. Smart city concepts started to trend some years ago and are increasing in popularity. 5G and Edge also are seen as essential technology boosts for those projects, and that’s why network vendors and carriers are involved in most projects. Smart cities are seen as a good reason to build technology infrastructure to collect, transfer and analyze all that data. Cities target to collect data and analyze it to optimize services and operations for many purposes, such as traffic management, public transportation, power consumption and production, water supply, waste collection, crime reduction, healthcare and community services. Environmental aspects are also becoming more critical. Air quality, noise pollution and consumption of energy are other areas cities want to improve. This all sounds great, but as we know from many other technology projects, it’s very different to focusing on the development of services for individuals, the user experience, and their unique needs and values. Beyond that, privacy and data protection are now critical issues in these kinds of huge data projects. At worst, smart city infrastructure resembles a real ‘big brother’ scenario. It is possible to build smart cities that serve individuals better, but it would require parties to develop services from a consumer’s perspective. The concept could help people get better services, optimize their movements, live healthier lives, save time and money and improve the quality of life in many ways. Ten years ago, we had to rely on mobile app developers to provide useful apps to individuals because carriers and network vendors were not able or motivated to do it. Many services would also become more valuable if we were able to combine personal and public data. Your movements combined with traffic and public transportation data, air quality data with your daily walking and running routes, and your personal habits with daily energy consumption peaks are just some examples. Together, the two data sources could create value for the individual and society. This could be achieved if individuals had access to public data combined with their own personal data. In this way, privacy could be respected and preserved. But if public services start to surveil individual people, we immediately encounter data protection and privacy risks. It would also lead to a model that cities, authorities and service providers would plan what they think is suitable for individuals, not to offer tools for individuals to improve their own lives. For city authorities, infrastructure vendors and carriers that dominate projects, it is not easy or conducive for them to build systems from an individual’s point of view. Of course, politicians in the city councils should be thinking of the residents they represent, but it’s not enough. We also need technology solutions and vendors that focus on building solutions and services for individuals. This would likely involve an additional layer for the services. Maybe something similar to app stores made for mobile apps that also enable users to protect their privacy and manage their personal data. It could also empower many other parties to develop services for residents and give them the power to decide what services they want to use. The best services are hardly ever developed by authorities and big tech companies deciding on what the individual wants. Smart cities should be focused more on the needs of residents. There are many ‘nice’ and ambitious plans to make cities and the lives of residents better, but nice plans are never enough. The real questions are who are the actual customers, who can decide which services to use and who will control the data. To make these services beneficial for people, the concepts, technology, architecture, data and business models should be designed to empower people, not just to surveil and control them.  Non-fungible tokens (NFTs), have gathered a lot of interest recently. They certify digital assets, including millions of dollars of digital art pieces. Christie’s has already sold an NFT work of art by Beeple. Of course, it raises the question, is this something more concrete than Initial Coin Offerings or ICOs in 2017. NFTs are digital certificates on a digital ledger, or blockchain, that proves a digital asset to be unique and therefore not interchangeable. NFTs are used to represent and certify photos, videos, audio and other types of digital files. Art is currently getting all the publicity, but NFTs can certify many other items, including text, software code or even Twitter tweets. The fundamental idea is that a digital object can be tokenized, and it becomes unique in that way. It is, in principle, not possible to make further copies of it. Some people have commented that the value and irony of NFTs is that although their name is non-fungible, they are easily fungible. They can be unique, but it is easy to trade them. And as we know, things can have value and liquidity if there is enough demand and supply and transactions costs are low enough. Many of us can still remember the 2017 ICO boom when companies started to offer their own tokens. Typically, they were startups (or not even startups but startup ideas) with business plans (called white papers). They included a token as an important component of their business plans and then started to sell those tokens. Some projects were able to collect significant money and, in rare cases, built a long term business. Many people participated in ICOs to learn how to buy a token, not thinking of its ROI. Some people had many bitcoins, and some had a hard time selling them (because they had no idea how they had acquired them) and wanted to diversify to other tokens. A fundamental difference between NFTs and ICOs is that ICO tokens usually represent only some future promises. NFTs represent assets, especially digital assets. In that way, buyers can evaluate how they see the value of their assets. It is always complex to evaluate the value of art, and NFT art has precisely the same challenges. Then there are many other digital items like pieces of music, virtual items in games and software components that can have an NFT. There are also plans to expand the NFT concept from virtual and digital items. There could also be digital certificates to represent physical items, for example, a certificate to prove real estate ownership. This part requires a legal framework that enables the use of this kind of digital certificate. NFTs have also generated crowdfunding plans. People and companies could sell fractions of their work, for example, music, movies or software. NFTs can make this market more effective, but it doesn’t remove all crowdfunding challenges, especially how to find the correct value and then make the secondary market liquid. It is also good to remember the model can work for some items that have enough supply and demand, but it doesn’t mean NFTs alone guarantee them for any item. There are several new business plan ideas based on NFTs. For example, if software is published as an NFT, there could be a new GitHub, especially for NFT software. Companies and individuals could start to license data as NFT packages, and media companies could also offer NFT content. Ethereum, which is based on the proof-of-stake model, is the most commonly used solution for NFTs. Blockchain still has fundamental questions around which solutions have a long term future and value. When blockchain software is updated, and a fork created, backward compatibility is an important question. A soft fork means a new version is backward compatible, and a hard fork means it is not. If a new version is not backward compatible, then old tokens won’t work in the new system. In the end, it is the community of each token that can decide which updates and forks take place. The fundamental question for each blockchain solution is its future backward compatibility. At the moment, Ethereum looks like a safe bet to implement blockchain-based solutions. With lesser-known blockchains, it is harder to predict their future. The NFT concept is more concrete and makes it easier to evaluate items than ICOs did. But in the end, an NFT’s value depends on the underlying items, so it is impossible to say if an NFT as such represents something valuable or only empty promises. NFT is an excellent model to manage and trade the value of digital items. But it is crucial to remember that an NFT alone doesn’t create value for a digital item. The items must have value, and NFTs help to make the value tangible. The article first appeared on Disruptive.Asia.  Crypto ATM at Crypto Valley in Zug, Switzerland. The COVID-19 pandemic has been significant for wearable devices. They have helped to detect early COVID-19 symptoms, and they have also helped people live healthier lives and take care of their wellbeing during the pandemic. The last 18 months have been a good time for many digital services, from video conferences to food delivery apps. Maybe it will permanently change how we manage our wellness and health and help mobile healthcare become mainstream. Higher resting heart rate and body temperature are early signs of COVID. For example, research institutes and universities have developed software to use Oura ring data to detect these early symptoms. Employers have also bought wearable devices for employees to detect early symptoms and warn them not to work if there are warning signs. This is the case in companies from customer and health care services to professional sports teams. Wearable manufacturers have reported that, based on their data, the COVID situation has also helped some people sleep better. The reason might be that people don’t need to hurry to work and take the kids to school in the morning. But we have also seen, as the situation continues, more people feel stress, i.e. based on data, have a higher heart rate (HR) and don’t sleep as well. The situation has also changed exercising habits. People don’t walk to work or take public transportation, no daily breaks to go for lunch or coffee. Health professionals are worried people are sitting too much during the pandemic. Others have started to exercise more, not daily walks but daily runs. This has resulted in more sports injuries. All this has prompted people to monitor their daily wellness and health data. People have also hesitated to see a doctor or go to the hospital but monitored their health with a smartwatch to measure heart rate or ECG (electrocardiogram). And if you have a Zoom call with your doctor, it is actually useful that you have that data at hand (so to speak). This all demonstrates that people have started to use more of these devices and are getting more data, but it’s not that simple. What should I interpret from my heart rate or heart rate variability? Do I exercise too little or too much? Is my sleep quality and exercising linked to each other? What is the data combination that really indicates some illness? When people get more data, it doesn’t mean they suddenly become health, sleep, diet and wellness experts. Some people might feel so when they Google health care instructions, but it can make things worse. This data can be beneficial for health and wellness monitoring, but it needs better software to analyze it or make it available for professionals. Mobile healthcare has been a hot topic for years, but COVID time has really brought it to the fore. Healthcare organizations tend to be rather conservative in taking on new things, but this period has forced them to find new solutions quickly. I know many mobile healthcare startups that have struggled for years. One big problem has been that healthcare organizations move slowly, making them difficult customers for agile startups. The other problem is getting access to reliable and accurate data. Many of those companies have offered solutions to transfer data to a doctor or hospital, but often people have to capture the data themselves, e.g. measure their glucose, blood pressure, heart rate and enter it into an app. Some people find this challenging, and others are just too lazy to do it. And there are those who might want to ‘fix’ their own numbers to either avoid embarrassment or show off. So, now we have more data, and we have solutions to transfer the data. But we still have a couple of problems: 1) privacy and data security for sensitive wellness data, and 2) more systematic models to utilize data, not only from one but several wearable devices. This means we need solutions to collect and combine data from several devices, combine that data and at the same time protect privacy. It would also help if this data could be combined in the future with other health care data like health history. With new technology and concepts, it typically takes years to make the breakthrough. It often also needs some special triggers to get things to happen. I remember the first great mobile health tech visions 20 years ago with 3G hype. Now it looks like the pandemic has helped us over some major obstacles, and the wearable market has also developed rapidly. We should now see rapid and significant development with more applications and services using wellness data more effectively, with a subsequent boost to mobile healthcare. The article first appeared on Disruptive.Asia.  It’s not expensive to buy a spy, according to a recent article. You can ‘buy’ a spy for $10,000 a year, or in more significant cases, you may need to pay $40,000 to $70,000, especially if the spy takes a considerable risk. There are other motives for people wanting to sell or give information, not just for military and international politics secrets. Human beings are a significant security risk for businesses. Can we do something to improve this weakest link? Colonel Vladimir Vetrov was one of the most important spies during the cold war. He worked for the KGB and leaked more than 3,000 pages of documents to French intelligence, including the names of more than 400 Soviet operating agents. He operated from 1981-82, and it is said his information went direct to President Reagan. He played an essential role in exposing weaknesses in the Soviet Union, its dependence on stealing western technology and how an accelerating arms race was driving it to collapse. However, it seems Colonel Vetrov didn’t do this for the money. He received some small gifts that he gave to his mistress, but nothing significant. He was more embittered with his career development at the KGB and also frustrated by the Soviet system. Several studies and cases demonstrate that embitterment is often a more important motive for spies to leak information than simple greed. Edward Snowden leaked highly classified information. His motivation was not clear, and now that he is now in Russia, he has indicated he was unhappy that the US authorities spied on its own people. Wikileaks also received leaked information from other people working in governmental agencies. Governments and enterprises spend a lot of money developing better solutions for physical and cybersecurity that are becoming increasingly significant. And these investments are definitely needed. But at the same time, it is important to remember; it’s people that leak information and create holes in even the most sophisticated systems. I have personally seen cases of spying or information leaking during my career. Once, a person at a customer leaked information from our competitors and how some people in the organization worked with the other vendors because he was not happy about his position. In another case, a company warned us that a cleaner in our project office had collected documents and photos from our bid documents. In one extreme case, someone set off a fire alarm in an office, and several laptops of a new project team went missing. All these are old cases. The question is, who can you trust? It is not an easy question to answer, and it is not black and white. Even the most loyal person can change and start to leak information. We could also say that no one is totally reliable; most people reveal information at some point, either intentionally or unintentionally. One solution is to keep people loyal. A good salary helps, but even more important is to make people feel they are being treated fairly. Companies try to identify problems to keep their employees loyal and reliable, but it is rarely enough. That raises the question as to what information is relevant. Many companies hide information that is not very relevant to anyone, competitors or customers. And those parties can usually get that information quite easily, so it is not a good investment to try to hide it at a high cost. It can also increase the risks of leaks if employees feel that irrelevant information is being classified as secret. There are technology solutions to avoid, identify and reveal spying and information leaks. For example, one old method is to make each copy of the information (e.g. a document) unique in order to identify whose document was leaked. It is also important to track who has copied some confidential information or had access to a system. There are other solutions, e.g. identifying unusual behavior, setting test traps or monitoring communications. It doesn’t make any sense for companies to take similar measures as critical governmental agencies if it creates ‘bad spirit’ in the organization. One big risk area nowadays is employees using their own devices and personal communication tools. Several simple solutions make sense. Suppose sensitive discussions between business partners preparing a bid, between a company and its law firm, or amongst board members take place via a messaging app, a Facebook group or another similar service. In that case, it increases the risk of inadvertently sharing information with other parties. Sometimes it can happen accidentally, especially when people are handling multiple groups and discussions simultaneously. It is not realistic in many of these cases to force people to use higher security tools which can be challenging to enforce between organizations. Most security tools have been designed for use within an organization. Technology is not the only solution to stop people from leaking confidential information. But technology can help to avoid accidental sharing, easy leaking and identify the sources of leaks. These solutions must be easy to use, and they must work with commercial off-the-shelf (COTS) technologies and services. They can help keep information in closed groups, prevent direct sharing, and identify if someone has shared confidential information. Security and trust in people is not black or white, more like shades of grey. There will always be people who want to spy and leak information, whatever it takes. But for the majority, it probably helps to have clear rules, better tools and increase the risk of getting caught. Any company that invests in building security in its physical and cyber environments must also think about building and monitoring trust with its people.  We are all probably skeptical about people who tell us what we should do because they think it’s what is best for us. A good example is adults telling kids and teenagers what to do and not to do to protect them. Apple and Google are doing something similar with privacy. They want to be consumers’ parent to protect their privacy, but they want to keep control. Do consumers really want this, or would they like to control what to do with and where to use their own data? Here lies an opportunity for a new data business. Apple is introducing new models in the latest iOS versions for users to control the trackers of mobile apps. Basically, a user must allow apps to follow them around the web, collect data and target other apps. Not surprisingly, there are estimates that around 70% of people, if asked, would not allow tracking of this type so that Apple may be onto something. However, this also increases Apple’s control of the ecosystem and makes it even more a closed-garden system by giving Apple control over what app vendors can do and how they do it. This would have an impact on other companies like Facebook and Tencent, which operate online advertising. Facebook has already warned, this would affect its revenue. Tencent and other Chinese mobile internet companies have developed workarounds for the model. Google’s Chrome will shortly stop supporting third-party cookies, making it harder to track users on the web. Simultaneously, Google is preparing new solutions to track the browsing history and profile and segment users, enabling advertisers to target ads better. This is coming from Google’s Privacy Sandbox project and gives Google a more critical role in the advertising ecosystem, making it harder for smaller ad companies and advertisers to work independently. Privacy and user tracking resemble something from the ‘wild west’. It becomes more complex when a few companies can control a significant part of the internet and mobile ecosystems. This may be specifically about web tracking and ad targeting, but Apple’s Health app collects data from wearable apps and enables downloading of health records, and Google Fit aims to do the same. All this opens the opportunity for a new unholy alliance between consumers and enterprises. Consumers could share their profiles direct with businesses and bypass the internet companies if they could see concrete benefits. This is not a new idea, but it needs easy solutions to become a reality. It is unlikely consumers will do something just for better privacy; they will want to see those benefits quickly. Let’s take a few examples of what this business and consumer cooperation could mean:
These are a few examples of how users can have a direct data relationship without the internet and mobile giants trying to control it. But consumers will need tools to collect their data and share profiles (not raw data). It can’t be something each individual negotiates with enterprises who would dominate, and consumers wouldn’t know the right price to demand. Consumers need weapons (i.e. tools and models) to do this properly. Ideally, this would be an open ecosystem with open source tools, open APIs in an open environment where different parties and developers could provide the means for consumers to keep their data. All this opens the door to new technology and companies to offer solutions for consumers and enterprises. Could this be the most significant change in the data business since the early days of the internet? Regulators could also accelerate this development by introducing new privacy rules, giving more power to consumers to control their data and restricting the internet giants’ dominating market position. Current privacy and data discussions and developments can confusing. Even though parties exist that want to protect consumers, they often add restrictions that make their lives more complex, particularly if they continuously need to click approvals. At the same time, data analytics offer more opportunities to consumers and businesses alike to better utilize data for better services, better prices, and make lives easier. The motives of some ‘protectors’ are not very clear and maybe not as ‘innocent’ or as ‘honorable’ as they might appear. There also lies the possibility of ‘data dominance’ simply moving from one actor to another. Long term solutions for data and privacy cannot be based on the controls and restrictions of a few big companies. Consumers must be able to control and utilize their data. All kinds of companies must also be able to use data if they can offer value to consumers. Otherwise, not only advertising but many other areas, including health and finance services, could also end up in the control of the internet giants. The article was first published on Disruptive.Asia. 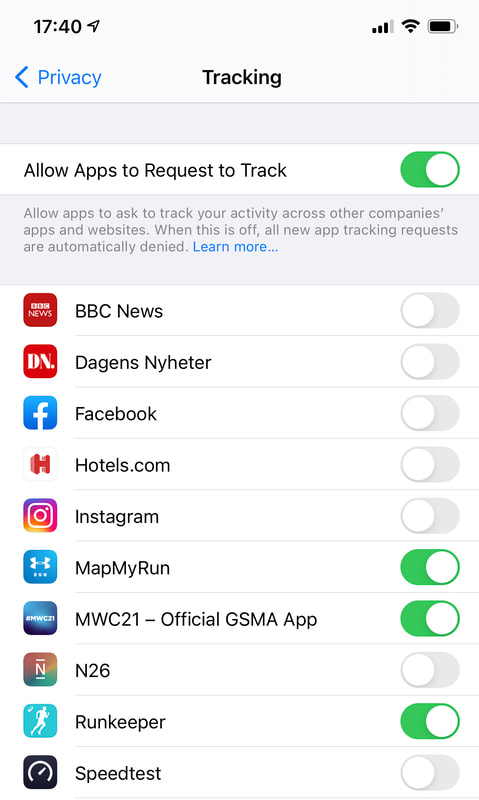 |
AboutEst. 2009 Grow VC Group is building truly global digital businesses. The focus is especially on digitization, data and fintech services. We have very hands-on approach to build businesses and we always want to make them global, scale-up and have the real entrepreneurial spirit. Download
Research Report 1/2018: Distributed Technologies - Changing Finance and the Internet Research Report 1/2017: Machines, Asia And Fintech: Rise of Globalization and Protectionism as a Consequence Fintech Hybrid Finance Whitepaper Fintech And Digital Finance Insight & Vision Whitepaper Learn More About Our Companies: Archives
January 2023
Categories |

 RSS Feed
RSS Feed
|
Digital Intelligence Globally
|

© 2009-2023 Grow VC Operations Ltd. All Rights Reserved.
|