|
As we’ve followed the trends in server-side applications over the past few years, one of the most significant innovations that is now being promoted heavily by all the major cloud service providers is the concept of “serverless” architectures. Having spent some time over the past few years testing this new approach Crowd Valley’s newest API version, which is being rolled out to selected customers and partners at the moment, will be fully serverless by benefitting from such cloud services as AWS Lambda and Microsoft Azure Functions. There are at least two clear DevOps advantages of this approach. First, it removes the requirement for you to control your own application servers; and second, it enables the parallelisation of your development and release processes. The joy of relinquishing control Running an API that uses a serverless architecture does not of course mean that there are no servers involved; rather, the servers that run your API code are no longer your problem. Instead, your application is broken into multiple functions, each of which run somewhere in the cloud in a way that makes the function available as and when it is needed. Immediately this is a huge advantage if you are moving from the paradigm of server applications running on managed servers, even if you use Docker containers. Primarily it means no longer need to concern yourself with specific server failure: the servers that actually run your serverless function code are managed by the cloud service provider so a server that fails is replaced without any impact on the availability of your function, and any necessary software upgrades or operating system depreciations are silently handled in the same way. As long as your function code fits the format that is required by the cloud service provider then the provider essentially guarantees that it will be available, usage limits notwithstanding. Similarly, scaling up your service no longer means that you need to know or care about how many servers are required because the scaling happens behind the scenes as and when your function is invoked at higher volume. Anyone involved in DevOps has seen how complex it can be to manage large deployments of servers with occasionally unpredictable usage levels, and by accepting the offer that is now made by cloud service providers to make it their problem – for which, it goes without saying, they have far more sophisticated tools and processes than most of their customers – engineers can really focus on the minutiae of deploying and scaling functions rather than on the boxes that contain them. Developers don’t need to talk With standard server-based or containerized applications the notion of a development ‘sprint’ is vital to ensure that you can stick to a regular release schedule. A sprint is the list of bug fixes or new features that are allocated to a given release, and once everything in the list has been completed and tested then the release package can be made and subsequently deployed. Since a release deployment updates the whole application, some organization is required here to ensure that all the various features and updates are in sync at the end of the sprint. In other words, since every bug fix or new feature is just one part of the whole application, and since on each release the whole application is deployed, if one small feature is not quite working or only partially finished at the end of your sprint then it can hold up the entire release. With a serverless architecture, every function of your API runs independently. There is no central application that deploys every function at the same time, and so a bug fix in one function can be developed, tested and deployed with literally no effect on any other function in your service. As a result, developer teams can organize around specialist areas of your service, with their own sprints and deployment processes, safe in the knowledge that the other teams will not be affected (obviously, solid test routines remain a good idea). This means that bug fixes can be deployed to production faster because they do not necessarily need to be part of a fixed release schedule, and longer-term, so-called ‘epic’ product innovations can have their own schedule that is entirely independent from the normal weekly or monthly release plan. Beyond the basics We would expect the majority of development teams to see at least these two advantages when moving to a serverless architecture, and there are certainly many more that we are finding every day thanks to the particular setup that we have implemented at Crowd Valley. We see this evolution as part of the technology industry’s inexorable move towards a better and more stable online service architecture, and at Crowd Valley we are excited to be building on top of it to create a finance infrastructure that will be the foundation for the new generation of online finance products and services. Written by Crowd Valley CTO Paul Higgins, originally published on Crowd Valley Blog. Read more about Crowd Valley's cloud based finance back office as a service here. 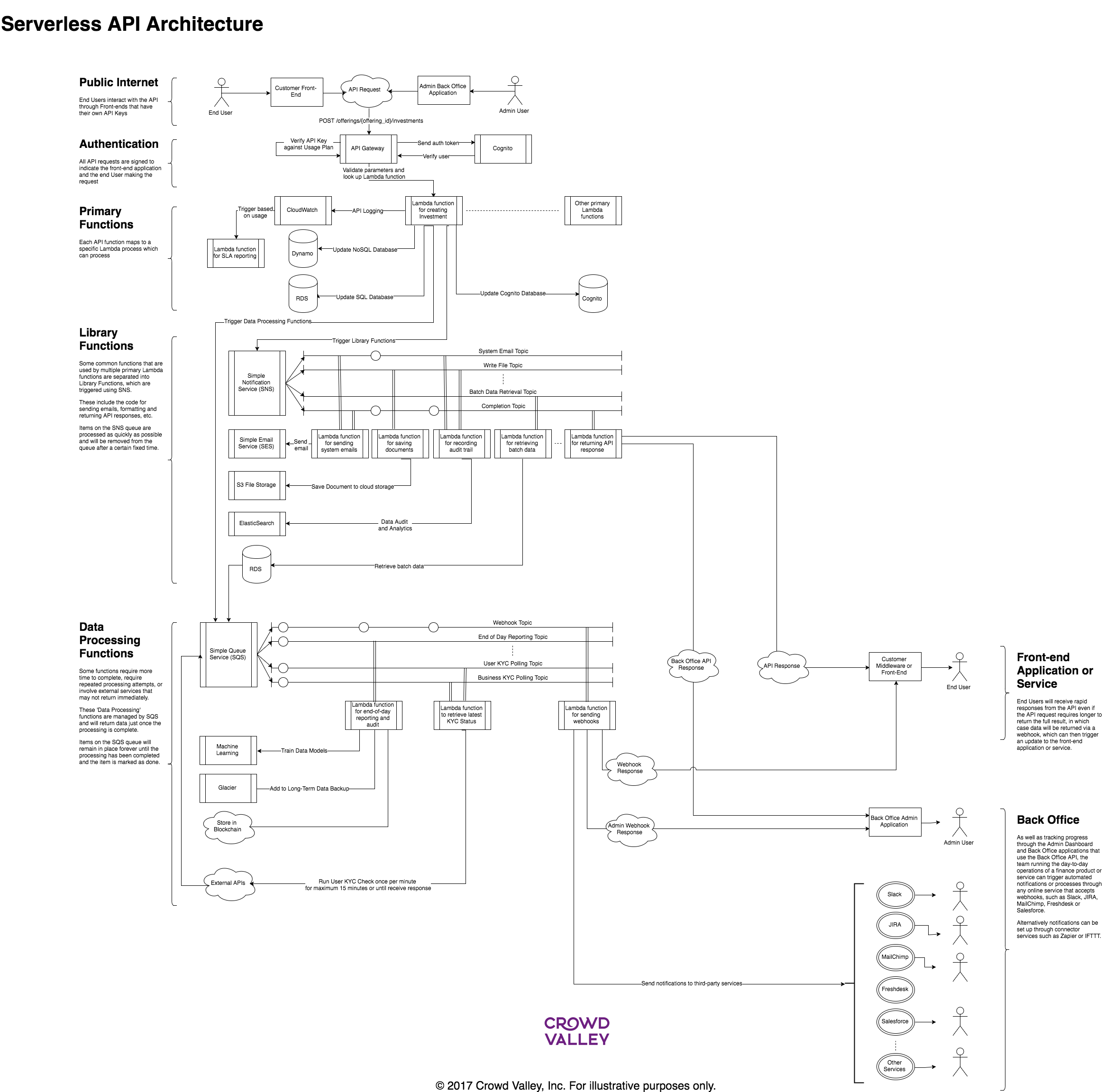 |
AboutEst. 2009 Grow VC Group is building truly global digital businesses. The focus is especially on digitization, data and fintech services. We have very hands-on approach to build businesses and we always want to make them global, scale-up and have the real entrepreneurial spirit. Download
Research Report 1/2018: Distributed Technologies - Changing Finance and the Internet Research Report 1/2017: Machines, Asia And Fintech: Rise of Globalization and Protectionism as a Consequence Fintech Hybrid Finance Whitepaper Fintech And Digital Finance Insight & Vision Whitepaper Learn More About Our Companies: Archives
January 2023
Categories |

 RSS Feed
RSS Feed
|
Digital Intelligence Globally
|

© 2009-2023 Grow VC Operations Ltd. All Rights Reserved.
|